1.
What is
“Relation” Anyway?
A relation can be considered a mathematical set which contains elements that are not ordered, not duplicated and not decomposable.
Relations can be visually presented as a table, or a spread sheet. In such tables, the rows have no order, no two rows are the same, and each row cannot be decomposed, which means, modifying any column of the row will make that row a different one. In other words, each row represents an atomic entity. The import point of relational thinking is to deal with a group of rows as a set, not with each individual row.
2.
SQL Server
SQL server, or sometimes database server, is a single process running on the server machine, storing and manipulating data, and managing data integrity and recovery.
SQL server maps logical layout of data to physical storage, and saves data in 2K-16K pages. When requests come from client, SQL server internally locates the page and takes the actions. When sizes of page change, SQL server can automatically split or merge the pages, all being transparent to the client.
SQL server saves system information in a set of system tables, including table descriptions, access permission, commands that create views, stored procedures, rules, defaults and triggers, and index definitions. It also contains many system stored procedures.
SQL server uses a connection-based concurrent access mechanism. For each connection, SQL server maintains a separate internal control structure, and switch among connection contexts to serve concurrent request. Each connection costs about 50K to 60K, plus some additional cache. There can be only one transaction per connection, and concurrent accesses to data from different transaction of different connections are protected by database internal locks.
3.
Handle Queries
High performance is a key factor of any database server; therefore most database servers will analyze and optimize the queries before executing them, based on query structure, table structure, indexes and the distribution of data.
Usually SQL server processes a query in the following steps:
(1) Parse the query into an internal tree structure.
(2) Use cost-based algorithms to determine the indexes and table access orders so that number of physical and logical IO can be minimized.
(3) Generate a query plan and makes it executable.
(4) Execute the query plan and extract the data from the database.
(5) Package the data and send it back to client.
4.
Handle
Transactions
A transaction is one SQL command or a group of SQL commands whose effects are made to database in an all or none fashion. All transactions satisfy the ACID test.
Atomicity: Either all the changes or none of them are made to database.
Consistency: Changes made by a transaction to database must leave the database in a valid and consistent state.
Isolation: Transactions are executed sequentially for any given data in database.
Durability: After a transaction is committed, the changes must be made physically to database.
Transaction isolation is achieved by database server internal locks. SQL server takes care of the most part, but users still have some ways to influence. There are usually five levels of granularity in data partition: database, extent, table, page and row. An extent is usually a set of eight pages. A page is usually 2 to 16 Kbytes. Locks can be applied at each level. The higher the level the lock is used, the low the concurrency.
To improve concurrency, user shall avoid lengthy transactions and complicated queries that across large number of tables. If possible, always use stored procedures to handle transaction so that the back-and-forth interaction between client and server can be minimized. Plus, handle all the runtime inputs, outputs, checks, error handlings in the stored procedure. Within a transaction, never return the condition back to client and prompt the user to make the decision.
5.
Set Isolation
Levels
Besides optimizing transactions themselves, isolation level is another factor that affects database concurrency. Isolation levels specify the rules about what a transaction can do when there is any another transaction running at the same time.
|
Level 0 |
READ
UNCOMMITTED |
Allow dirty read - one
transaction reads data that are modified but not yet committed by another
transaction. |
Maximum
Concurrency |
|
Level 1 |
READ
COMMITTED |
Allow one transaction
read data that are modified by another transaction only after the changes are
committed. |
SQL
Default |
|
Level 2 |
REPEATABLE
READS |
The row read during transaction A cannot be
changed by other transactions until A is complete, but transaction A can see the new rows
inserted and committed by other transactions (phantom read allowed). |
Incorporated
to Level 3 by SQL |
|
Level 3 |
SERIALIZABLE |
Concurrent transactions are totally isolated and
each has its “private” copy of data when it starts. No change will be exposed until committed.
No transaction will see changes committed by other transactions until it is complete (phantom
read not allowed). Concurrent transactions run in a serial fashion and one update may roll
back if the data have been changed by another transaction. |
Minimum
Concurrency |
6.
Data Modeling
Data modeling is the process of identifying atomic entities, defining attributes for entities, and determining the relationships among entities. The end results are definitions of attributes, entities and entity relationships, presented in the well known entity-relationship (E-R) diagrams, such as the following example.
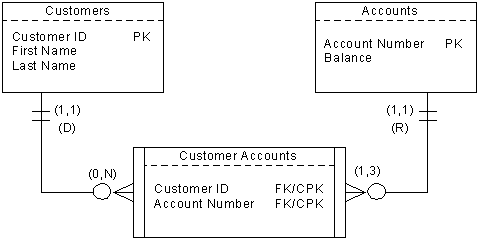
After identify attributes, entities and relationships, we can map entities to tables, attributes to table fields, and relationships to joins or relation tables. Select one attribute or a set of attributes as the primary key. The way to build relationship is to include the primary key of one table as an attribute of another table, the so-called foreign key.
Relationship shall only be one-to-many or many-to-one. If there is a one-to-one relationship between entities, consider merging them. If the relationship is many-to-many, use relation table to break it into one-to-many and many-to-one. For example, order and product are many to many relationships. One order contains multiple line items, and each item corresponds to one product. Therefore one order can correspond to multiple products, and one product can appear in more than one order. To break the many-to-many relationship, we can create a line item table, which uses the order number and product number as the composite key. Now order table to line item table is one-to-many, and line item table to product table is many-to-one.
7.
Normalization
Normalization is part of the data modeling process to cut data duplication and protect data integrity. The results are smaller tables (fewer rows), fewer null values, and less data redundancy. Normalization helps to achieve easy management and high performance.
The first normal form requires that every field must be atomized, which means it cannot be further decomposed, and no two fields can have the same meaning. Examples of violating the first case are: field called “name”, which can be decomposed to “first name” and “last name”; field called “phone number”, which can be decomposed to “area code” and “phone number”; field called “address”, which can be decomposed to “street”, “city”, “state”; field called “locations”, which has the value such as “Location1, Location2, Location3”. Non-decomposed fields make queries on part of their values (e.g., “area code”) very difficult. Example of violating the second case is fields named “product 1”, “product 2”, etc. Multiple fields of the same logical type make queries on those fields impossible.
The second normal form only applies to tables that use composite key. It requires that every field must be valid according to the composite key, not just one of the fields in the composite key. Take the line item table as an example. It uses the order number and the product number as the composite key. A field called “unit” would be qualified by the second normal form, because it belongs to the line item. On the hand, a field called “ship date” may be qualified if the shop ships by line items (even though multiple line items may have the same ship date), or may not be qualified if the shop only ships the whole order. For the latter, “ship date” only depends on the order number and shall belong to the order table. This example shows that normalization may also depend on the business rules. The first solution cost more storage space because one order can have many line items, especially if it turns out most line items are indeed shipped on the same date. Nevertheless, it is more flexible. Here again we see the classical tradeoff between flexibility and resource cost.
The third normal form requires that every field of the table must be directly related to the key field; otherwise, it shall be moved to a different table. For example, it makes sense to add a “supplier” field to the product table. But adding a “supplier address” field to the product table violates the third normal form because the address depends on the supplier not the product – two products with the same supplier will have the address duplicated in the “supplier address” field. . The right way is to create a new table called supplier, which may have fields such as “supplier number”, “name”, “street”, “city”, “state”, “zip”, “area code” and “phone number”. Make the “supplier number” primary key of the supplier table and foreign key of the product table.
The fourth normal form is to eliminate the kind of many-to-many relationship within a table. One way to do that is to break the table into several tables, each of them has the same key field but different properties. For example, a Product table with fields like “origin” and “color” violates the fourth normal form because the origin and color are independent with each other therefore for each product there can be a suite of rows covering all the possible combinations of the origin and color. The right way is to break the Product table into the ProductOrigins and ProductColors tables, both have the “product ID” as the primary key. However, if the two fields such as “origin” and “price” are not independent, it would make sense to put them in the same table (for example, a ProductPrices table).
8.
SQL Statement
Examples
Create Table
CREATE TABLE Person
(Employee_Id SystemId NOT NULL,
Last_Name CHAR(20) NOT NULL,
First_Name CHAR(20) NOT NULL,
Middle_Name CHAR(20) NULL,
Age INT NULL)
Insert Data
INSERT INTO Person
(Employee_Id, Last_Name, First_Name, Middle_Name, Age)
VALUES
(101, ‘Bond’, ‘James’, ‘F’, 48)
Get Data
SELECT Last_Name, First_Name FROM Person
WHERE Age < 65
Update Data
UPDATE Person
Set Age = 49
WHERE Last_Name = ‘Bond’ and First_Name = ‘James’
Delete Data
DELETE FROM Person
WHERE Employee_Id = 101