Physical database design takes the tables, fields and table relationships developed in the logical database design, and establishes the storage mechanism, physical layout, database paramters and indexing strategy. Since physical design must be done on a particular database management system (DBMS), the first action of physical design is to select a proper DBMS. All the outcomes of physical design are targeted at the chosen DBMS. Here we use Oracle as an example.
Different Views of Data Storage
From user’s point of view, data are stored in database as sets of logical objects called schema objects. Schema objects include tables, views, sequences, synonyms, indexes, clusters, database links, snapshots, procedures, functions, and packages. A schema is a collection of schema objects by a particular user for a certain database.
From Oracle’s point of view, data are stored in logical storage and physical storage. Logically, data are grouped in tablespaces, which consists of data blocks, the basic unit of logical storage in terms of I/O operations.
Extent is a logical representation of a number of contiguous data blocks that is used for allocation when the storage is extended.
Segment is a logical representation of a set of extents that serves a usage purpose, such as data segment, index segment, rollback segment and temporary segment.
Tablespace A
Table A
User’s
View
Index A
![]()
![]() (Schema)
(Schema)
![]()


![]()
![]()
![]()
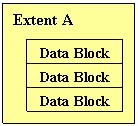
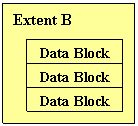
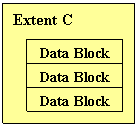 Oracle’s
View
Oracle’s
View
(Logical Storage)

Datafile B
Oracle’s View
Datafile A
(Physical Storage)
There are certain traces from user’s view to Oracle’s view and from logical storage to physical storage. A tablespace can contain objects from different schemas, and the objects for a schema can be contained in different tablespaces. Oracle automatically allocates one data segment for each table, which size (number of extents) is defined by STORAGE_CLAUSE of table or tablespace.
Note that there are can be multiple segments in a tablespace, and a schema object (table, index, etc) can be allocated among multiple segments, from the same tablespace or different tablespaces. Oracle supports unlimited number of extents in a segment, but the practical maximum number is 4096.
Tablespace Related Operations
Tablespace can be easily created, altered and dropped. Before create a tablespace, create a directory structure so that you know exactly where you will put the datafile. When create a tablespace, you must at least specify the datafile. Directory part of the datafile name must exist; otherwise Oracle will complain: “The system cannot find the path specified.” If the datafile does not exist in file system yet, you must specify the size of the file you want to create and operating system will create a file with the size no exactly the same (a littler larger than) your size. Note that the size of the datafile being created is not the same as the initial extent, which is specified in the storage clause. The name of the datafile is totally free form. Two other useful clauses are “extent management local” and “nologging”.
The relationship between a tablespace and the datafile can be easily changed with “alter tablespace”. Use “alter tablespace” to take the tablespace offline, change the datafile to a different one, and then put the tablesapce online again. After the tablespace is offline, the datafile can be moved or renamed using file system as wish.
To drop a tablespace, first use “alter tablespace X offline normal;” to take it offline, then use “drop tablespace X including contents cascade constraints;” to drop the tablespace.
Use “select * from dba_tablespaces;” to list all the tablespaces in the database. Use “select * from V$datafile;” to list all the datafiles in the database.
The size of the tablespace can be changed in two ways: one is to add more datafiles, “alter tablespace X add datafile ‘c:\oracle\data\X2.dat’ size 10 M;”; the other is to increase the size of existing datafile. This is done through the alter database SQL statement – “alter database datafile ‘c:\oracle\data\X2.dat’ resize 20 M;”
A schema is a set of tables created by a particular user (including “sys”, “system” and users with or without DBA privileges). It can be found out by SQL statement “select * from user_tables;”. A schema is only visible and accessible to the user who creates it. For example, a set of tables created by user “system” won’t appear to user “dev”.
On the other hand, tablespaces can be created by any user with DBA privileges, and once created, are visible and accessible to all the users. So even though you can drop a tablespace thus drop all the tables belonging to that tablespace, doing so would be intrusive to many users. The better way is to logging as a particular user and letting that user drop the tables created by him.
Define Database Parameters
In Oracle, static parameter files end with extension .ora, such as init.ora and config.ora. Changes made to static parameter files take effect only after the database is shut down and restarted. Dynamic parameter files have the convention as SPFile<DbName>.ora. Changes to these files cannot be made directly like those static files, but through SQL*Plus commands. The changes take effect right away.
Users control the logical storage allocation (in units of extents), while the physical storage allocation (in units of datafiles) are done by Oracle and hidden from users. Users affect logical storage allocation by defining storage parameters. At the highest level are the database parameters, usually defined in init.ora file. They determine the fundamental storage configuration for the entire database, without specifying number of extents. The second level is the tablespace, defined in the STORAGE clause of the CREATE TABLESPACE statement. They determine the extent allocation policy for all the segments in the tablespace. The third or lowest level is the table or index level, defined in the STORAGE clause of the CREATE TABLE or CREATE INDEX statement. They determine the extent allocation policy for the data segment associated with the table or the index segment associated with index. Parameters defined at lower level override those defined at higher level. To summarize, logical storage allocation is performed at segment in unit of extent, but configured at table or tablespace in unit of extent.
The db_block_size parameter defines the size of data block. On modern computers with plenty of memories, it could be 4, 8, 16 or even 32 K bytes. After the db_block_size is set, it cannot be changed unless the database is rebuilt. After Oracle 9i, you can set different block size for each tablespaces (default to db_block_size), but the SYSTEM tablespace must use the default block size defined by db_block_size. Data block contains header for various housekeeping information. The average overhead of data block due to header ranges from 84 to 107 bytes.
Database parameters can be viewed using view V$PARAMETER.
Data Storage Management
Oracle uses a ring type of segments to manage information rollback. When all extends of a segment have been used, Oracle only reuses the first extent if the information saved in that extent has been obsolete. Otherwise, it allocates a new extent. The segment can take on lots of space when there are many uncommitted transactions, but can be shrunk back to the original size by setting the optimal parameter or explicitly using the shrink command. But the extension and shrinkage of rollback segment is usually the source of database fragmentation. Oracle 9i introduces the automatic rollback segment management, which is done through the Undo tablespace. You have the choice to use either rollback segment or Undo tablespace, but not both. Set parameter UNDO_MANAGEMENT to AUTO for Undo tablespace and to MANUAL for rollback segment. Undo tablespace can be created as part of the database creation, or can be created separately and the name be added parameter UNDO_TABLESPACE. When creating it, explicitly specify the size, such as 200 MB. If it is not specified but undo management is used, Oracle by default creates one called SYS_UNDOTBS, with AUTOEXTEND turned on and initial size of 10 MB. Parameter UNDO_RETENTION (default as 900 seconds) determines how old the uncommitted transaction can be overridden when space is not sufficient in UNDO tablespace. When it does happen, you see the ORA-1555 “Snapshot too old” error. Note that the higher this parameter, the more uncommitted transactions can be allowed, and the bigger the size of data blocks, the bigger the UNDO tablespace. You can have more than one datafile for one UNDO tablespace but only one can be active. You can switch from one such tablespace to another. Note that no database users other than SYS can access (read or write) rollback segments.
Oracle records all changes made to data blocks, including those of rollback segment, in the redo log. This second recording of the rollback information is very important for active transactions (not yet committed or rolled back) at the time of a system crash. If a system crash occurs, Oracle automatically restores the rollback segment information, including the rollback entries for active transactions, as part of instance or media recovery. Once the recovery is complete, Oracle performs the actual rollbacks of transactions that had been neither committed nor rolled back at the time of the system crash.
For sorting operations, the intermediary data that are less than sort_area_size are buffered in process global area (PGA). Otherwise, Oracle writes the data in chunks to disk, allocating temporary segment.
Before Oracle 8.0, objects shall be grouped into tablespaces by types, such as one tablespace for tables and another for indexes. After 8.0, people tend to group objects by size, for example, small-size objects in one tablespace, and mid-size objects in another. It makes sense to combine them: use size first, and then type.
To minimize fragmentation, the extent sizes of all the objects in a tablespace shall be multiples of each other. The convenient way to do that is to define a proper Min_Extlen and make all extent sizes multiples of that.
Performance of small lookup tables can be increased with table caching. Turning off logging for table creation and other direct-load changes can also improve performance. Tables that are cached cannot have logging turned off.
Trailing nulls in a row require no storage because the header of the next row signals that the remaining columns in the previous row are null. For example, if the last three columns of a table are null, no information is stored for those columns. In tables with many columns, the columns more likely to contain nulls should be defined as the last to conserve disk space. But the column of datatype LONG will always be stored by Oracle as the last column, therefore cancel the benefits of storing null columns as the last. Plus, any newly added columns will be stored at last, also cancel the benefits.
When you create an index, Oracle automatically allocates an index segment to hold the index's data in a tablespace. The tablespace of an index's segment is either the owner's default tablespace or a tablespace specifically named in the CREATE INDEX statement. Data and index of a data shall be stored in different tablespaces, and even better, different disk drivers, so that Oracle can retrieve both index and table data in parallel.
Extent Fragmentation
A tablespace is fragmented at extent level if enough size of space exists in the tablespace but because the extents are not contiguous, the space cannot be used to satisfy storage request. The best solution for extent fragmentation is to avoid it in the first place. Following the Simple Algorithm for Fragmentation Elimination (SAFE), we can eliminate extent fragmentation entirely. As a result, we shall never de-fragment the tablespace, i.e., moves all the free space in one extent to the end of the datafile.
The SAFE rules include:
1. Use unified extent size. All the segments in a tablespace shall have exactly the same extent size, which means in the storage clause, the NEXT value shall be the same as the INITIAL value, and the PCTINCREASE value shall be 0.
2. Avoid small size extents. Always specify a value for MINIMUM EXTENT of a tablespace so that the size of allocated extent will always be a multiple of that value.
3. Consolidate definition of extent size. Define storage clauses at the tablespace level only; don’t do that at the table level. Let the tables inherit their extent definition from the tablesapce. However, MINEXTENTS can be specified at table’s storage clause to guarantee the amount of space for a table, but it will be in the number of extents, not the size of each extent itself.
4. Use the golden extent size (160K, 5120K, 160M, increased by a factor of 32). The principle is to use small number of large size extents, instead of a large number of small size extents. In Oracle 8, the following rules of thumb make things a little simpler. Segments smaller than 128M shall use 128K extent size, between 128M an 4G use 4M extent size, and larger than 4G use 128M extent size. Another golden number is 1024. That is the number of extents in a segment when that segment shall be relocated.
5. Don’t put user data in the System tablespace. The System tablespace contains the database meta-data. Oracle does not follow the SAFE rules in the System table therefore it is essential that do not put user data in the System tablespace so that extent fragmentation cannot occur there.
6. Set the size of datafile a multiple of the tablespace extent size plus one block. Because Oracle uses the first block of each datafile to maintain bookkeeping information, it would generate extent fragmentation even though the tablespace uses uniform extent size. If we use extent size 160K, and we estimate the total size of the tablespace- in multiple of 160K – will be 16M, and the block size we choose is 4096 (4K), then the size of the datafile shall be 16,004K. If autoextend is enabled for a datafile, make sure the maximum size of the datafile is a multiple of the tablespace extent size plus one block. Use the default value of AUTOEXTEND NEXT (one block), or set it to the multiple of extent size.
Indexes
Index helps accelerating data retrieval. Arguably speaking, index has the biggest impact on database performance. Without index, a column can only be scanned sequentially. But index does have overhead. It requires extra storage, especially the non-clustered index, and INSERT, UPDATE and DELETE operations can result in index update, which cost performance.
Indexes are logically and physically independent of the data in the associated table. You can create or drop an index at any time without affecting the tables or other indexes. As a matter of fact, indexes shall be created after all the initial data of the associated table have been populated so that indexes do not have to be updated every time a new row is added. Indexes are stored in their own segment, the index segment.
Index can be added to any column or set of columns, but for one particular combination of columns (including single column) there can be no more than one index. That is to say, indexes of (columnA, columnB) and (columnB, columnA) are two valid indexes. Unique index can be added to unique columns only. In fact, unique index is the only way SQL server can guarantee the uniqueness of a column. That is why people normally put unique index on the primary key. Only when the primary key is not frequently used in query and user application can guarantee the uniqueness (which is very rare case), unique index shall be removed from the primary key column or columns. Unique index does not have more overhead than non-unique index. Other than keeping the uniqueness, unique index can help the query optimizer. For example, whenever the first matched row is found, the searching is over; there is not need to search for the second match.
The cases for using indexes:
(1) For uniqueness of any column or columns.
(2) On frequently queried columns, usually the primary key and foreign key.
(3) On columns in join party.
(4) On columns that are frequently used on sorting, grouping and range checking.
Pitfalls of using indexes:
(1) Too many indexes (more than five indexes for any given table).
(2) Index on table with fewer than five pages. SQL server will usually ignore index and do a table scan.
(3) Index for “future” use or unjustified benefits. Remember index does cost time and space.
(4) On compound index (index on more than one column), the first column is not the most selective.
(5) Index on table of which more than 5% to 15% of rows need to be read. SQL server will usually ignore index and do a table scan.
Clustered index determines the physical order of the rows of a table therefore one table can have no more than one clustered index. Since it is aligned with the physical order, it has little storage overhead and higher performance. Clustered index is the single best shot for high performance, and indeed, there can be more than one for each table. But when rows are added or deleted, clustered index must be updated, which can be quite expensive. Clustered index is called index-organized table in Oracle, and the table is organized alone the primary key, which implies that Oracle always puts the “clustered index” on the primary key. Non-clustered indexes on a table that defines one clustered index are equivalent the secondary indexes on index-organized table in Oracle.
On the other hand, non-clustered indexes are references to rows. Each table can have multiple non-clustered indexes. Non-clustered indexes have much larger storage overhead (maybe ten times than clustered index), but because of the extra level of indirection, adding or deleting rows has less impact on non-clustered indexes.
To choose between the two types of indexes, consider the real difference between them. Clustered indexes contain the rows directly, therefore are faster than non-clustered indexes in the case of locating rows, which are actually references to those rows. But this one level of indirection plays little role in determining which types of index to use. What are more important are their relations to the physical layout of rows. Clustered indexes have the same layout of physical layout, therefore contiguous rows have contiguous clustered indexes, and rows on the same page have their clustered indexed on the same page – where the name “clustered” come from. Therefore clustered indexes are very efficient in “chunk” operation, such as range check or ordering. This also implies that clustered indexes affect the physical layout of rows.
Without clustered indexes, rows are stored sequentially in the order of inserting, and pages are linked like a chain. All new rows are added to the last page, when the last page is used, a new last page is created. When rows are deleted, they are moved from whichever pages they are in, leaving “holes” behind. With clustered indexes, rows are reorganized with index update, resulting in fewer pages and condensed layout. Another inclusion is that clustered index shall not be added to rows that are sequential in nature, such as date and serial number. Because such rows will end up in sequence even if clustered index is used. The result is that all inserts will happen on the same page (hotspot), which increases the lock contentions. So try to avoid using clustered index on sequential column that have heavy insert activities.
To summarize, use clustered index when:
(1) The column is involved heavily in “chunk” operation.
(2) High performance is needed.
(3) Want to better organize the rows – less holes, less hotspots.
In any cases, if the column needs to be unique, use unique clustered index.
One example is an Account table, which has a primary key column AccountId, and one extra column Balance. Even though lots of queries will be done on the primary key, they are mostly single-row operation, such as “where AccountId = 101”. For this reason, non-clustered index shall be used, even though it has one more indirection than clustered index. Remember you can only define one clustered index per table, so use it wisely. On the other hand, the Balance column would be heavily used in “chunk” operation, for example, special gifts for accounts “where Balance >= 10000 and Balance <= 100000”.
All the other purposes served by indexes other than clustered index can be achieved by non-clustered index, namely,
(1) Single-row operation.
(2) Uniqueness.
(3) Need more than one index to improve performance, usually the primary key.
(4) Improve the query performance.
One interesting case called “index covering” states that if all the columns appeared in a query are part of a compound non-clustered index and the search argument can be worked on the index, the index covers the query. In such case, query can be performed on the index page thus improve the performance, especially the leading column of the compound index is listed first in the search argument.
Another thing about non-clustered indexes is that they can be put on a different segment than the data so that data access and index access are on different devices. Note that clustered index must be on the same segment as the data.
All fields that are unique or primary keys require indexes. Foreign key fields almost always use indexes too. When one field is defined as unique or primary key, a unique index will be automatically created for that field if there is not one yet, but for performance reasons, you should explicitly create the index. Note that unique or primary key field can use non-unique index too, but there must be one unique index to enforce the uniqueness.