Logical design is to refine the data models with a particular database technology. Usually it means the translation from entity to table, from attribute to field, and from instance to record. Since a particular database technology imposes certain constraints, the main concern in this phase is how to come up with a logical model that is optimized to that particular database.
Translate Entities to Tables
Usually it is quite straightforward to map entities to tables. However, sometimes one entity can map to separate tables. One reason is for control of access. You may want to put some attributes of the entity that can be seen by one group of people into one table, and other attributes that cannot be seen into a separate table. Another reason is for the different access characteristics: the DSS type and the OLTP type. DSS type attributes are static and read heavy, such as system configuration, customer information, regulations, etc. OLTP type entities are more dynamic and write heavy, such as operation history, statistics, transaction record, etc. DSS and OLTP type of attributes shall not locate in the same table for access efficiency.
Translate Attributes to Fields
Realize that field is a kind of global thing – visible in the entire database. One field can appear in more than one table, usually for table correlation purpose: primary key in one table and foreign key in another. Note that field shall appear in multiple tables only for table correlation purpose. When one field appears in multiple tables, they shall be the same type, be assigned the same type of index, even use the same field name.
Minimize redundant data. Data redundancy refers to the case that within one table, some fields of multiple records have the same values but other fields of the same set of records have different values. Redundant data are unavoidable. If go to the extreme case, every non-unique field by definition can have redundant data. Data redundancy usually means a big portion of the records have the same data. To minimize redundant data, move the fields whose values are different to a separate table, so that the fields left in the table can have their records consolidated.
Minimize duplicated data. Data duplication refers to the case that between two tables that are related by the primary key/foreign key association, the table that has the foreign key has some fields from the primary key table, therefore certain data of one record in the primary key table also appear in the record of the foreign key table. The right way is to remove the duplicated fields from the foreign key table and use the primary/foreign key association to get the data from the primary key table.
Eliminate multi-value fields. Multi-value fields are those of the same meaning but appear as “type1”, “type2”, “type3”, with the appendix number potentially open-ended. The problems are: (1) It is hard to sort or search among type1, 2 or 3 because they are fields not records. (2) It is hard to add a new field (e.g., “type4”) because we have to change the table definition. (3) Since it is hard to differentiate the values in type1, 2 or 3, data are randomly scattered among them which makes the searching really inefficient – you have to go through all the three fields to make sure you get all the data. One common mistake of multi-value fields is the report-style tables. For example, the manufacturing people would regularly check the consumption rates of their parts, say, every hour for the last 24 hours. The report is usually in the format that each part takes one row and each row has 24 columns, each corresponds to one hour. But table that contains the data is seldom designed in that way. The basic principle is that data and information are two different things. Data are the raw materials stored in database, information is the cooked meal delivered to the consumer. One data design (tables) must support different types of information presentation (reports), but they are seldom the same. For some special cases that none of the above three problems apply, multi-value fields design is acceptable. One example is the “First Name”, “Last Name” design. The way to eliminate multi-value fields is to define “type” as the field and 1, 2 and 3 as the records.
Eliminate multi-part fields. Multi-part fields are those whose values contain more than one independent, same type values. For example, put “red, blue, yellow” for the field “Color”. Note that this is different from the name case, because first name and last name are not independent to each other, and the candidate values of first name and last name are very board, while the candidate values of color are very limited. The solution is to break multi-part fields to multi-value fields then deal with them using method described above.
Type of Participation
When two tables are related through the primary key and foreign key association, the table containing the record of which the primary key is used is the parent table, the table containing the record of which the foreign key is used is the child table. The relationship has a dependency on the existence of the two tables. The participation of one table is mandatory if at least one record must exist in the table before the related records can be entered into the other table. The participation of one table is optional if such requirement does not exist. Usually participation of the parent table is mandatory, while participation of the child table is optional. But sometimes the parent table can be optional too. For example, the parent table is the department, and the child table is the employee, and one employee, when first hired, may not belong to any department. In such case, the participation of department table is optional. Another way to think about is that mandatory participation is exclusive containment – no child without parents, and optional participation is nonexclusive containment – orphans without parents. For mandatory participation, the foreign key in the child table cannot be null, while for optional participation, it can.
Degree of Participation
When two tables are related, degree of participation describes the minimum number and maximum number of records in one table that can be related to one record in the other table. For example, if the bank requires that each account must have at least one but no more than 3 owners, and each customer can have from zero up to unlimited number of accounts with the bank, then
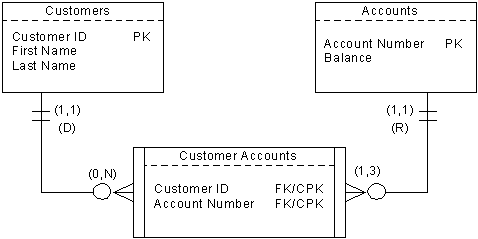
Each customer (a record in the Customers table) may appear zero to unlimited times in the Customer Accounts table. Each account (a record in the Accounts table) must appear at least one time but cannot appear more than 3 times. On the other hand, each record in the Customer Accounts table must trace back to one and only one record in the Customers and Accounts tables. Customers can exist without an account at all (sales group will be very interested in this group of people). An account will be created first and then assigned to one to three customers. So the in their relationships with the Customer Accounts table, accounts must exist first, therefore their participations are mandatory. The bank requires that customers shall never be deleted - so that it can bother them forever, and if the customers want to be deleted, mark them as “inactive”. The bank also requires that an account can be deleted only when all its owners have given up their ownerships. So the deletion rules are deny from Customers to Customer Accounts, and restricted from Accounts to Customer Accounts – if there is at least one record in the Customer Accounts table contains the reference to a certain account, that account cannot be deleted.
Deletion Rules
When two tables are related through the primary key and foreign key association, the participation of each table can be mandatory or optional. Records in the optional- participation table can be deleted without restriction, but deleting records in the mandatory-participation table would leave the related records in the other table “homeless”. The deletion rules are part of the business rules that guide such situations.
D – Deny, refuse to delete the record in the mandatory table; instead, make it “inactive”.
R – Restrict, refuse to delete the record in the mandatory table if the optional table contains related records.
C – Cascade, delete the record in the mandatory table and also the related record in the optional table.
N – Nullify, delete the record in the mandatory table and then set the foreign key of the related record in the optional table to null.
S – Set default, delete the record in the mandatory table and then set the foreign key of the related record in the optional table to default value.
Validation Table
Validation table, or lookup table, is used to enforce a
range type business rules. For example, when you enter the state of your
residence for online registration, you normally select one from a drop down
list, instead of type the name of the state yourself. In this way the online
company can be sure that you can only enter a valid state. Validation table
usually has two entities, the key and the value, for example MI and
Relation Table
Relation table corresponds to the linking entity. It is used to break the many-to-many relationship to two one-to-many relationships.
Data Types
Data types can be SQL server built-in or user-defined. Several factors determine the right data type for a field: functions, size, and performance.
Primarily, we select the right type for a field based on the purpose of that column. A social society number or telephone number can be either character or numeric. Since very likely we will perform string operation (substring) instead of numeric operation (e.g., sqrt), we better use the character type. However, on the other hand, if we don’t do any string operation, we may choose to use numeric type, for size consideration, because an SSN takes 9 bytes in character type and 4 bytes in numeric type, and numeric comparison is much faster than string comparison.
Some rules of thumbs are: (1) Use the smallest size possible. If smallint can do the work, don’t use int. (2) Prefer numeric type to character type, since numeric type takes smaller size and compares faster. (3) Prefer fixed length type to variable length type. The balance is between size and performance. Variable length has more runtime overhead, especially when the field is changed frequently, but more efficient in space usage, since fixed length type will pad zeros to reach the unified length. If a field has relatively uniformed size for all the data, use the fixed length type; otherwise, consider using the variable length. If the field will be modified frequently, use the fixed length; otherwise, use the variable length. SQL server has two bytes of overhead for each variable char, defining 1, 2 or 3-character string as varchar does not make much sense. 4 or 5-character string can be defined as char if the field is quite filled. Field beyond 5 characters is most likely defined as varchar. Some people claim that varchar is buffered in memory and transmitted through network in its full length, only when it will be stored on disk, RLE will compress it. (4) Try to use the same type (including the “null status”) for the fields that serve the same purpose, especially when the fields are in different tables and are comparison parties in join statement.
Null Value and Null Status
Null value indicates that the data of a particular field is not available, no more, no less. A null should not be used to imply any other value, such as zero or empty string. Most comparisons between nulls and other values are by definition neither true nor false, but unknown. To identify nulls in SQL, use the IS NULL predicate. Use the SQL function NVL to convert nulls to non-null values.
The “null status” defines a particular field can be null or not. Note that “null status” plays important role in the size and performance of a field, therefore sometimes is considered part of the data type. For data types that have variable length (character and binary), fields that allow null value are treated as variable length, even though they may be defined as fixed length. When char is compared to varchar in a join statement, SQL server internally does the char to varchar conversion. For data types that do not have variable length, fields that allow null value can still have some overhead in storage.
When define a user data type, null status can be included in the definition, for example,
EXEC sp_addtype ‘nametype’, ‘varchar(25)’, ‘not null’
But remember the null status can be overridden when “nametype” is used, for example,
CREATE TABLE students (fname nametype null, lname nametype not null)
When create a table, always explicitly specify the null status for each and every field. This will help you and help others, and minimize confusions. When the null status is not specified, SQL server has the right to apply what it thinks. The default is not null. Since the default can be changed with sp_dboption or set statement, the behaviors of a table can be dramatically different even though the create table statement never changes – a surprise most people don’t like. Plus decide the null status at early and static stage helps unify the types for the columns in join party.
Stored Procedures
Stored procedure is a set of SQL statements that serves as a functional module and is stored and pre-processed by the server. Contrarily, a batch is just a set of SQL statements (between two “go” commands). Stored procedures can have inputs, returns, variables and flow controls (if/then, while, goto, etc.). They are parsed on creation and compiled at the first execution, therefore run much faster than a batch of statements. They can reduce network traffic, in terms of number of trips and the size of data being transferred, which is very important in a database transaction. They are modules and easy to develop, maintain and reuse. Stored procedures can have different user permissions than the underlying tables. One good practice is to assign more strict permission to tables than to stored procedures so that all the user access can be in a controlled environment through stored procedures. Compared to object-oriented concepts, tables are like private data, and stored procedures are like public methods. Of course, stored procedures can be private too.
Triggers
Triggers are like stored procedures, except that they are automatically fired at the INSERT, UPDATE and DELETE actions on a table. Triggers will be fired no matter how many records have been affected, including the case that none of the records are affected, e.g., try to delete a non-existing record. If multiple records are affected by the operation, the trigger is invoked once for all the records. It is a good idea to review a trigger in the situations of no record, one record and multiple records. Triggers are not under any permission type of access control, and no one, even the administrator can stop a trigger from firing. The only way to stop a trigger is to remove it.
Each table may have up to 3 triggers, each for INSERT, UPDATE and DELETE. Internally triggers have impacts on three tables, the target table, the inserted table and the deleted table. INSERT with trigger will add new records to both target and inserted tables. DELETE with trigger will remove the records from the target table and add the removed records to the deleted table. UPDATE with trigger will remove the existing records from the target table, add them to the deleted table, then add the new records to both the target table and inserted table. When triggers are invoked, all the actions have been taken place but the changes are not yet visible to the user since the pages or tables containing the changes are locked, until the triggers are completed.
Views
Views are virtual tables in database. To users, they are tables, with each field pre-defined and can be queried and modified just like a normal table. It is virtual because none of the data in the view are stored on disk. They are in memory and are dynamically pulled from the real table every time the view is used in user’s query. Therefore there are hidden queries behind each view to pull in those data.
Compare with using those queries explicitly by users, views are more efficient - database optimizer considers them perfect candidate for optimization and can cache them in memory for reuse. Views are more reliable – keep out of the hands of users, more secure – keep user from accessing the underlying tables directly, and more robust – when the query logics change, just modify the view implementation (how view is mapped to tables) not the view definition therefore users application does not need to change.
Compare with stored procedures, views are more like tables. Users can access them in the same way as accessing tables so that queries are easier to write and data structures are easier to comprehend. On the other hand, stored procedures are more flexible and can be applied to complicated process. So views are stored queries other than stored procedures.
Oracle is introducing the materialized view, the data of which are actually stored on disk. Materialized view can be regarded as a second-level table. They are good at pre-processing very large volume and complex, especially in the case that data are from different databases, different geographical locations, and some of them are static and some of them are dynamic. Think about your want to generate a report about the financial status of a particular company. Some information in the report is relatively static, such as the name, the address, line of business, number of employees and last year’s revenue. But if you want to impress your clients by adding fresh daily stock price to the report, you can use a materialized view to pull in all the static data, and on a daily basis pull in the stock price.